.png?width=3750&height=1323&name=Convai%20logo%20-%20final_Convai%20logo%20-%20final%20(1).png "Convai")





Old world
What is Voice Recognition?
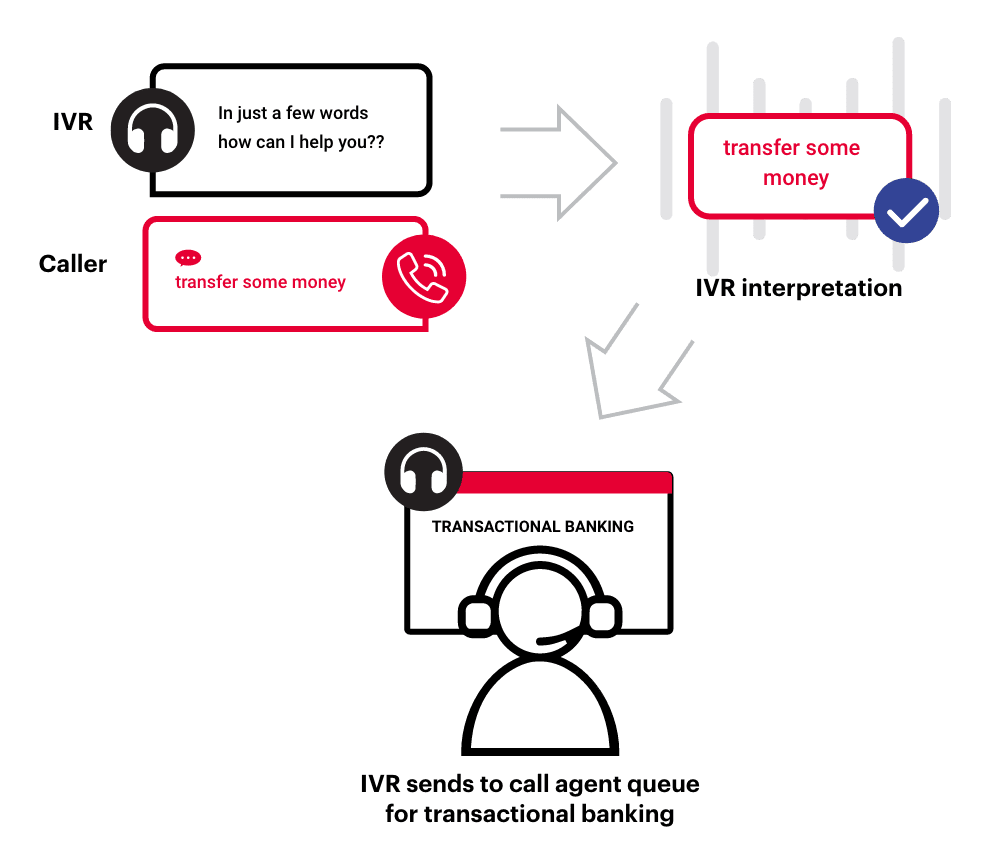
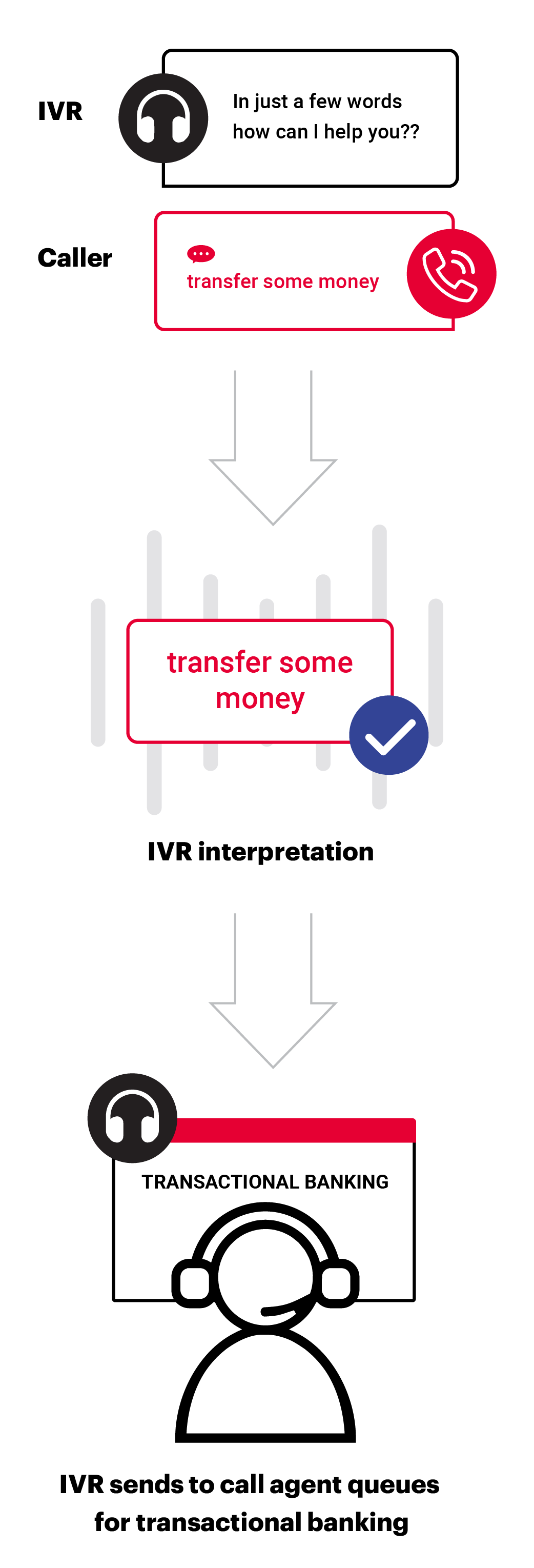
Voice recognition is the process of converting spoken language into text that can be processed by an application. Traditional voice recognition technologies have limitations. They require a complex ‘grammar’ to constrain the words that it might expect to hear, making it costly to implement and requiring regular tuning. As a result, the accuracy of traditional voice recognition is limited, and it is not always able to interpret natural language effectively. While voice recognition has been useful, it may not be the best long-term option for accurately interpreting spoken language.
New world
What is Transcription?
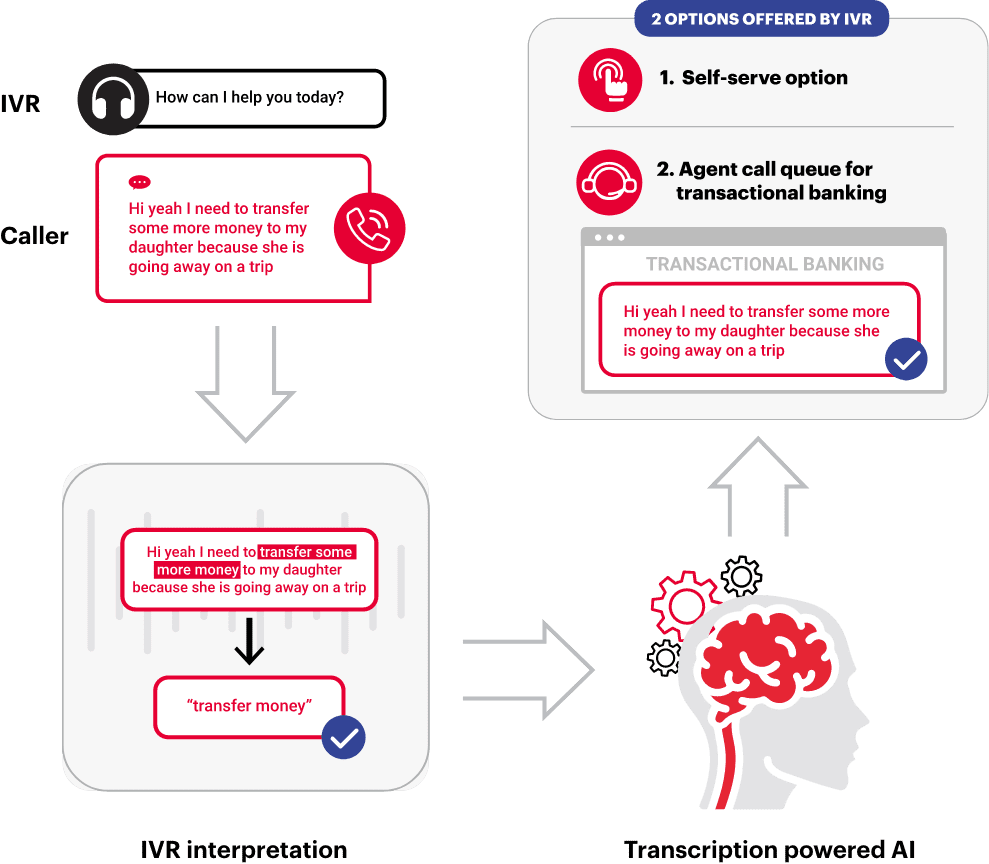
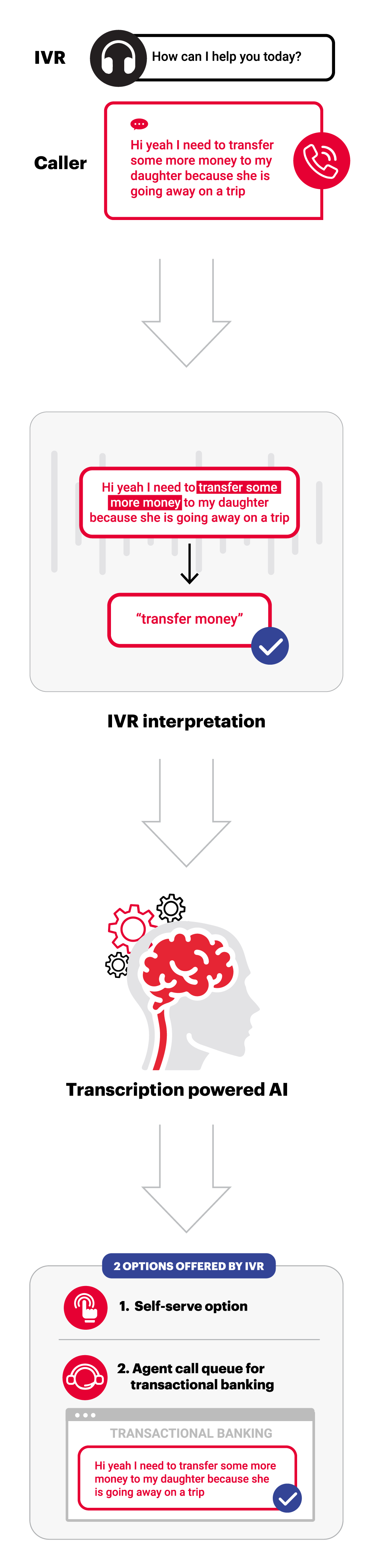
Transcription is the process of converting spoken language into written text much like VR. However, it is a new generation of technology that has emerged as a more flexible and effective alternative to traditional voice recognition. Unlike voice recognition, transcription does not require a complex ‘grammar’ to constrain the words that it might expect to hear, and it can transcribe almost any spoken word, including punctuation. This makes it more accurate and better at interpreting natural language. Transcription is used in various applications, including speech-to-text transcription tools, virtual assistants and customer service chatbots. With the rise of natural language processing and artificial intelligence, transcription is becoming an increasingly important technology in the field of human-computer interaction.
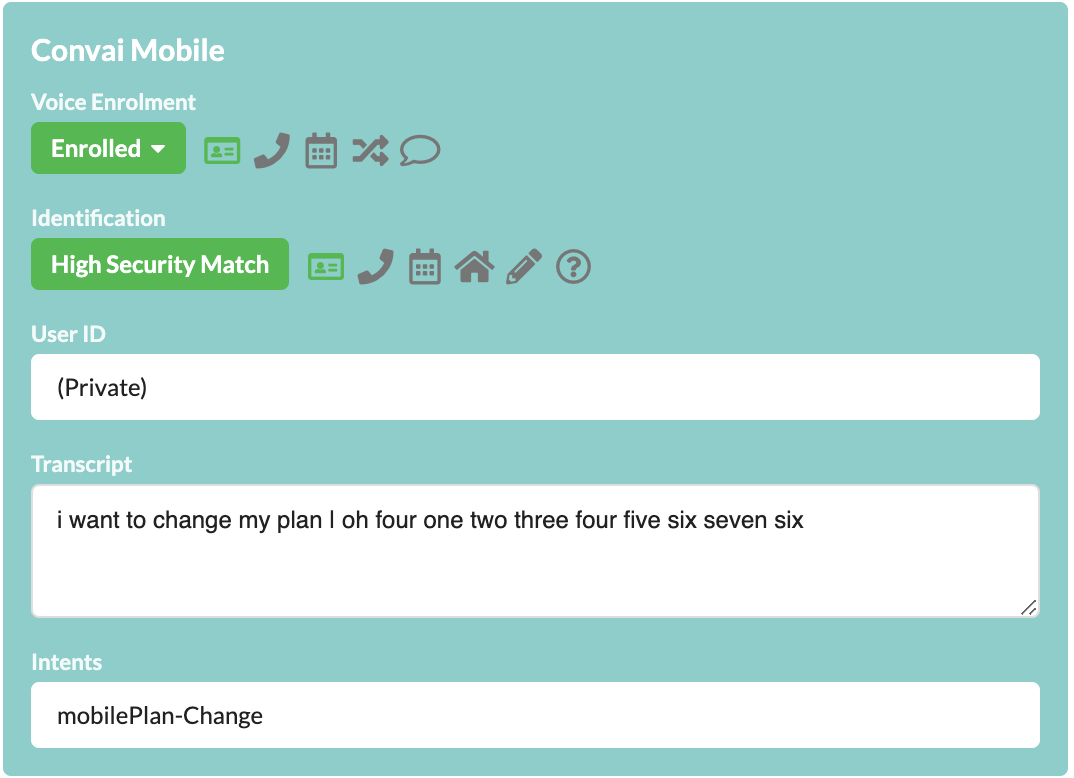
Oration will:
 Reduce average handling times
Reduce average handling times Identify and verify your callers
Identify and verify your callers  Increase uptake to self-service
Increase uptake to self-service  Provide targeted banners
Provide targeted banners  Facilitate a digital channel shift
Facilitate a digital channel shift  Improve agent and customer engagement
Improve agent and customer engagement  Support speed to competency
Support speed to competency
Discover Oration’s features
You can configure Oration’s features to your contact centre’s needs with or without Convai’s help - you choose what works best for you.

